Scrabble is nowhere close to a solved game
I have found that in the literature about games and AI (artificial intelligence) that Scrabble is invariably referred to as something of a “solved” game, in the same way that Chess, Go, etc are “solved” by AI —in these latter games, there exist AIs that have superhuman performance and can basically beat any person. Even an ML expert like David Silver (from the AlphaGo team that notoriously built the best Go and Chess AIs ever) refers to Scrabble as a game where superhuman performance has already been achieved: https://www.youtube.com/watch?v=ld28AU7DDB4&t=4m31s
There is always a relevant XKCD comic:
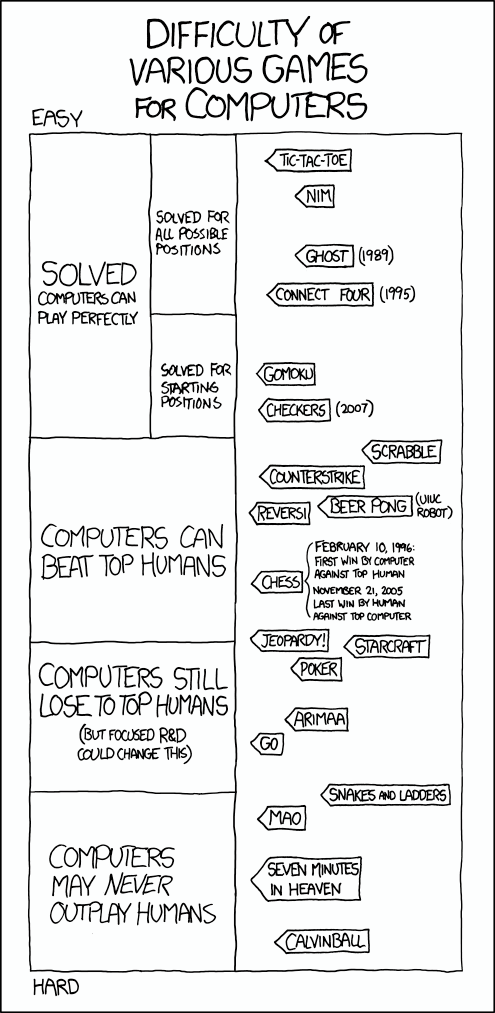
Although it is a little outdated (Go and Chess in particular should be ranked much higher), what is Scrabble doing all the way up there? I would put Scrabble where it currently puts Go or maybe a little above.
This perception of Scrabble AI is damaging, because researchers do not consider it to be a game worth looking into anymore. I believe a large part of this misconception comes from the seminal Maven paper (World-Championship Caliber Scrabble) by Brian Sheppard, published in 2002. In this paper, Brian, who spent years since the 1980s developing a top-level AI (Maven), outlines the process and results for his, admittedly excellent, program. He makes various conclusions:
- Maven is capable of super-human play
- Board factors are largely irrelevant (except for triple-word squares)
- To evaluate board openness accurately requires simulation
- Human masters miss 10 to 20% of their bingos (plays that utilize all their tiles, these get a 50-point bonus and it is crucial to learn them)
I believe that these, amongst other points in the paper, are not entirely accurate, and that there is a great deal of improvement to be made.
How does Maven work?
The methodology of Maven is relatively simple. There exist various Scrabble play-finding algorithms that can find all legal plays on a board, given the board position and current rack. The fastest one in the literature, which uses the GADDAG data structure, can find all moves on most boards in a matter of microseconds to milliseconds on any modern computer. I believe there are faster algorithms possible, but this is not considered to be a bottleneck for Scrabble AIs at the moment¹.
Maven will then sort the moves according to “equity”. Equity is a combination of the score of the play plus the value of the “leave”. For example, if your opening rack is AEIQRST, the highest scoring play available is QATS for 26 points, but the best play is far and away QI for 22, because the value of the left-over tiles (STARE) is significantly greater than the value of IRE (the tiles that would be left over after QATS). Maven determined the value of many leaves with a lot of self-play, and uses various formulae to determine the values of longer leaves that are not in its lookup tables.
Scrabble is a game of perfect information in the endgame — when the bag is empty, which makes it more akin to chess in this phase. You can theoretically figure out every move your opponent can make, and make your own moves in return. For this, Maven uses the B* search algorithm to solve the endgame.
With this system alone, one can make a very formidable player, that should beat most human masters close to 50% of the time. However, such an algorithm has no concept of defense or offense. It is possible to close the board and trap it so that it doesn’t know how to open the board. It is also possible to wait for it to make huge openings even when it’s ahead, to allow the human opponent to come back and win the game with a late bingo.
The big innovation that changed Scrabble is Monte Carlo lookahead on top of the above algorithm. After generating all the moves for a position and sorting them by equity (this step is called “static evaluation”²), Maven will establish a cut-off (say, the top 10 or 15 plays). For each of these plays, it will then draw random tiles for itself after making the play, then draw tiles for its opponent, make the highest equity play, and finally make its next play with its drawn tiles. It then compares the results across many iterations to come up with an accurate ranking of plays. The results in this case are simply the difference in scores after each iteration, plus a small adjustment based on tile leaves; it is fortunate that Scrabble has a good way to approximate the value of any given position (i.e. the current score difference).
Many times the top equity play is not the one that “simulates” best. One can extend the number of “plies” of look-ahead to go to the end of the game, but typically just 2 or 4 plies is enough to get accurate results.
With Maven’s release, many long-held wisdoms of Scrabble were proven false. It was the theory before Maven that playing as many tiles as possible was always best (within reason; people understood it wasn’t wise to waste Ss and blanks, and perhaps other really good tile combinations). Thus, someone with an opening rack of AAADERW might play WARED for 26 points, keeping AA. Maven showed that with simulation, AWA for 12, keeping ADER, jumps to the top of the plays, despite the 14-point sacrifice, as ADER results in many more bingos than AA in future turns³.
How has Scrabble changed?
Maven dramatically changed Scrabble and helped greatly in improving the play of those who used it. With the advent of computer studying programs, it is not uncommon for top players to have anagrammed every single word between 2 and 8 letters long multiple times, and many of them can go long stretches of games without missing a single bingo. I myself am not in the very top players, but I have still seen every bingo and have had a number of 1-day and even 2-day tournaments where I didn’t miss a bingo.
Unfortunately, Maven was always closed source, and after it was sold to a game company, the free version ceased being updated. In 2005 two expert players, John O’Laughlin and Jason Katz-Brown, set out to build an open source AI, called Quackle, based upon the same principles. One of the biggest improvements they made is something called “superleaves”, where the value of every possible 1-to-6 tile leave was determined after many millions of games worth of self-play. Quackle’s Monte Carlo simulation works the same as Maven’s.
At a 2006 Computers vs Humans tournament in Toronto, Quackle finished in first place, two games ahead of Maven. It also won its best-of-5 finals against champion David Boys. Although this does not conclusively prove Quackle is better than Maven, it is believed by most of the community that its improved leave values would have it beat Maven head-to-head, even if slightly. Quackle’s implementation of B* is a little buggy, and the pre-endgame solver does not always work, but it has good “timing” heuristics (i.e. it knows to leave 1 tile in the bag, and the values of leaving 1 vs 2 vs 3, etc. tiles in the bag in the pre-endgame, values it also determined through self-play). Even though Maven’s endgame and pre-endgame is apparently better, Quackle’s is good enough, and I estimate the number of blown games due to its imperfect endgame and pre-endgame engine to be no more than 1 in 1000.
Since Quackle’s release many players have used it to analyze their games and improve. However, Quackle has not really been updated in many years, besides small compatibility updates and additions of new dictionaries.
What is missing?
Twenty years after the Maven paper came out, it is now quite out of date. The level of play has improved significantly (due largely to Maven and Quackle). The paper also has not proved its claims that Maven is superhuman. It defeated a top player in a publicized match in 1998 (Adam Logan)— but there have been very few public computer vs human matches since then. The paper makes a few claims to prove its assertion that Maven is capable of superhuman play, but I don’t believe these all stand up to scrutiny.
For example, the following statistic is very out-of-date:
MAVEN averages 35.0 points per move. MAVEN-versus-MAVEN games are over in 10.5 moves per side on average. Each MAVEN plays 1.9 bingos per game. These statistics are considerably better than human experts. The best humans average around 33 points per move, 11.5 moves per game and about 1.5 bingos per game.
This is simply not true. The best player in the world, Nigel Richards, averages around 37.5 points per move and 2.16 bingos per game. Granted, this page contains statistics for the TWL (North American) and CSW (World English) lexicons combined; the latter has about 30% more words, so higher scores and bingos are more common. However, you can see TWL-only stats at pages such as the one for the LA Club #44 — see for example detailed statistics from 2011. You can see that it’s not uncommon to average over 2.1 bingos per game (BAVE column) and over 35 pts per turn (divide AVE by approximately 11 to 12 for the top players). The TWL dictionary has added more words since the Maven paper was released, but not nearly enough to account for this discrepancy. The truth of the matter is that Scrabble players have improved enough that it is worth revisiting the central thesis of the paper — that Maven is superhuman.
Maven’s de facto successor Quackle is excellent. In long series vs several top players it comes out ahead, even if slightly. Grandmaster Kenji Matsumoto played it to a best of 500 and Quackle beat him 252–248. As you can see, however, that is not something anyone would call “superhuman” play. I have found a misconception amongst laypeople (those not involved in Scrabble) that computers are much much stronger than we can ever be, but this is not the case. Even I, as a relative chump, can still trounce an AI — it is roughly as good as Maven’s or Quackle’s static evaluator⁴:

Quackle notably fails at understanding board dynamics. Although Sheppard posits that board considerations don’t matter, I don’t believe his point was really proven. One expert player has done various manual experiments with Quackle, for example, applying a simple heuristic in which he plays the move that has the lowest standard deviation (plus some human considerations if the player is behind, for example) after simulation, and has convincingly beaten Quackle’s standard Championship Player in a 250-game series (approximately 62–70% of the time, as the algorithm was being refined)⁵.
Because simulation requires the plays to be ranked accurately by equity, it is not always correct. Remember that the play it will pick for the opponent is always the highest equity play, but in many cases, a human opponent would never make the highest equity play (if, for example, it blows open the board). Hence, Quackle tends to overestimate chances of coming back, assuming the human opponent may randomly open a triple-triple for it, for example. Matsumoto has a very compelling page which shows an example list of situations that Quackle gets wrong. The ones at the bottom, after an opening play of FEW, are particularly eye-opening and may be easier to understand for a Scrabble layperson.
Additionally, Quackle does not play the endgame perfectly in situations where one of the players is stuck with a tile (and even in some rare situations where it has to find an out-in-two — i.e. use all its tiles in two plays). There is much to be done with endgames and pre-endgames. A program exists (by a company named Ortograf) that can exhaustively solve almost all endgames and up to 3-in-the bag pre-endgames, which is amazing. Sadly, it is closed source and not yet available for download/purchase, but it has been demonstrated to me and works great. I believe exhaustive endgame solving works better than the B* approach, which I was unable to reproduce myself. The Maven paper was sparse on details about its endgame algorithm, with paragraphs such as the following:
In effect, there was an optimistic evaluation and a pessimistic evaluation for every variation. The idea was that the true evaluation would be found within those bounds. Computing such bounds is tricky, but with sufficient test cases you can eventually make a system that almost always works.
I myself also worked on an exhaustive endgame solver. Even though it is much slower than Ortograf’s, it does solve most endgames very quickly. One interesting result I obtained involved the example endgame in the Maven paper; after several hours, it found a solution that was 1 point better than Maven’s⁶. There is a ton of work to be done on the endgame solver, as my algorithm is quite inefficient, but it was mostly done as a proof of concept. I believe Ortograf’s implementation would find a solution in a few minutes or perhaps even seconds.
Edit: We ran the algorithm again and it turns out the solution I had found was actually 7 points better than Maven’s. Ortograf found several that were NINE points better, after around 40 minutes of processing.⁷ There is a good question to ask here, admittedly — is it worth 40 minutes to get 9 more points back in the endgame when a standard tournament game is over after 25 minutes? Perhaps not, but it shows that there are solutions that are better than B* at solving Scrabble endgames, and that we could work on optimizing these.
There are other things that are missing from a world-class Scrabble engine:
- Automatic inferencing of racks / range-finding. It should be possible to roughly estimate what rack or range of letters your opponent kept after their play in many situations, assuming perfect play. There is a program named Elise that does pretty good range-finding, but there hasn’t been research on how this does against Quackle. I predict the range-finding components will do well. Sadly, Elise hasn’t been updated in almost 9 years, and there are some bugs in it that would make it difficult to run an automatic series of games against Quackle. Still, it should be attempted, at least manually.
- A way to determine the openness/closed-ness of a board. Sheppard posits that this doesn’t matter and that simulation determines the correct plays regardless. I really do not believe this is true. The “standard deviation” experiment I mentioned earlier shows that board considerations matter greatly in determining the accuracy of a simulation. The list of many board positions that simulation does not work on is also worth considering. I believe further research on this topic is definitely merited. Even if Maven was superior in most board positions, why not try to find a methodology that finds the best play in all situations?
- Adapting leave values to the current board shape and tiles left in the bag. Right now, Quackle (and my own AI, Macondo) have their own constant leave values for every possible leave. These do not change even if the bag is consonant-heavy, or vowel-heavy, or has many Ss, etc. The board can have bingo lanes, hotspots, right angles, closed quadrants. None of this is accounted for. For example, if the board doesn’t have any S hooks, the S should be less valuable. If the tile pool has no Us left, then the Q should be much less valuable. Even though simulation helps here, remember that the static evaluator is not evaluating the plays correctly, so simulation can only be so accurate.
- Machine learning can help. We haven’t even discussed the advancements done by AlphaGo and AlphaZero (tabula rasa learning of the game’s rules can eventually allow for superhuman play). There are many situations in Scrabble where we play by “feel”, depending on our opponent’s last few plays or even the time they took to make them and their general demeanor. People may purposefully sacrifice equity to block lanes because they feel their opponent is close to a bingo. In many situations where people do things “by feel”, I believe machine learning can provide a boost.
I believe that we can still create a Scrabble engine that can beat the state-of-the-art one (Quackle) 60+% of the time with a combination of old and new techniques. Additionally, we can make it as explainable as possible, so that players can learn from it. My dream goal would be to set up a sponsored match against the undisputed best player in the world (Nigel Richards).
The community
I am not the only one who believes Scrabble is not a “solved” game. I talked to a few people in the community about their thoughts. Matsumoto, who has a lot of experience playing with and analyzing Quackle, told me the following:
I have no doubt that some day Scrabble computers will achieve superhuman strength. But as of now, computers in Scrabble are far from reaching the levels of excellence that they have reached in other games, and their only ability to compete is based on their ability to consistently play-find.
As he said, I do concede that AIs do very well, largely due to their play-generation skill. This is very different than many other games. There’s no difficulty in generating plays in games such as chess, backgammon, go, etc. In those games, it is more about analyzing and comparing the legal plays that are available; whereas in Scrabble, even master-level players don’t immediately see all the best options. It is often the case in tournaments that we are spending our time during our turn just trying to generate plays that are better than what we currently see; comparing between a few different plays sometimes gets treated with less importance, likely due to having spent too much time coming up with that star play. And in Scrabble, the play that scores the most is often the best play. We’ve estimated that Scrabble is roughly 75% play-finding and 25% everything else. So computers definitely have an advantage in this aspect of the game, but that 25% “everything else” makes champions.
On our Woogles Discord server, the subject of Scrabble and AIs came up — in particular, the AlphaZero team’s YouTube video linked early in this article, and master player Joshua Sokol-Rubenstein chimed in with “wait a DeepMind guy thinks Scrabble is solved-ish? Jesus Christ we have work to do”.
What is next?
I would love to be able to pour some time and obtain funding for research of Scrabble and related crossword board games as they pertain to artificial intelligence. I’m not even saying funding for myself, but if there are any universities or researchers that are now convinced this is still a fertile ground, I would love to hear from you for potential collaboration.
There is clearly a lot to be done, and the game is far from being “solved”, as is commonly believed. If anyone is interested in collaborating on what I hope is the next-level Scrabble AI (Macondo, which is, of course, open source) please let me know.
[1]: A faster move generation algorithm might actually help a lot in an exhaustive endgame solver.
[2]: You might also see static evaluation being referred to as the “kibitzer” in some places. This was what the Maven software called it.
[3]: Since the addition of the word ADWARE, this simulation result is no longer as clear, but AWA is still best.
[4]: This game was played on https://woogles.io against HastyBot. Woogles is a pandemic project created by myself and a small group of Scrabblers. Note that this is played in the CSW21 lexicon, with which I am not as familiar, so my overall record against HastyBot tends to be only around 30% in this dictionary. I can beat it closer to 45% in NWL20, but probably 50% if I tried harder 😝
[5]: I personally have not verified this, but trust the person who did this and his methodology.
[6]: I had to track down a copy of the OSPD1 dictionary that was used for this endgame. The sequence is mostly the same, except mine plays U(R)N for 4 instead of (U)RN for 3 pts. It saves the R for (SURFAcE)R.
[7]: Ortograf’s solution is similar to mine, except they play (U)N for 2 points, still blocking ZI(TI). The R is saved for (SURFAcE)R and the U is saved for M(U), giving the un-stuck side a bunch more points.